Thread 'bug in server: report to project or to boinc?'
Message boards : Server programs : bug in server: report to project or to boinc?
Message board moderation
| Author | Message |
|---|---|
 Joseph Stateson Joseph StatesonSend message Joined: 27 Jun 08 Posts: 642 
|
Occasionally I find something strange but it could be just the way the project sets up the server. One bug I am sure about is that there seems to be a timing issue : (1)I make a venue change, the venue is picked up on the next project update but the contents of the venue are not acted upon during that data exchange. ie: if the new venue says "do not send x" I can get an "x" anyway but never again. This is difficult to repeat but I it has happened on several occasions. (2)If I create an app_confrig.xml that requires only "X" be downloaded I get an "X" anyway but thereafter only the correct "y" I think the server looks to see what to send me before it notices the venue changed or the existence of an app_config.xml but it has already made up its mind what to send me. For what it is worth I am pretty sure I can duplicate (2) It could be that some of these bug are in earlier server and projects are not always running the latest. I could not find any server code at GitHub but I might have missed it. ID: 93254 · |
|
Send message Joined: 5 Oct 06 Posts: 5164 
|
The server code is contained in the exact same BOINC/boinc repository at GitHub - you can also choose server_release/1/1.0 and server_release/1/1.2 branches if you want confirmed, stable, code. I'm not exactly sure what you're describing at a first, rushed reading. But I think it's a well-known and deeply embedded design decision, which it will be hard to change at this stage. The process goes: Make a change to project preferences, on the project website. Update the project in the client. It's wise to have 'No new tasks' set for this stage. This update ensures that the web preferences are transferred to the client. THEN allow new work, and update for a second time. The client will then request new work based on the new preferences. app_config.xml can't be used to control download choices. ID: 93256 · |
|
Joseph Stateson Send message Joined: 27 Jun 08 Posts: 642
|
The server code is contained in the exact same BOINC/boinc repository at GitHub - you can also choose server_release/1/1.0 and server_release/1/1.2 branches if you want confirmed, stable, code. Thanks, that helped me realize my problem. I did not know what to look for. After reading this guide I realized I had already downloaded the server code. What got me confused in the first place was when I was tracking down a possible bug in the milkyway project. I wanted to start with the message last request too soon and see where the problem came from. I could not find that phrase when using VS2013 "find in entire solution". I found that phrase on my ubuntu system. There is probably a way to do it under windows 10 but not with win10 "find" as it is not recursive AFAICT. jstateson@jyslinux1:~/Downloads/boinc-master/sched$ grep -r "last request too recent" . ./handle_request.cpp: "Not sending work - last request too recent: %f\n", diff ./handle_request.cpp: "Not sending work - last request too recent: %d sec", (int)diff I do not know how to get that source code into VS2013. I did the following search find -i "handle_request" *.vcxproj and could find any reference to any (c++) project. Since it ends in cpp I would have thought I could bring up VS2013 and look through the code. I am pretty sure I know what is going on and could help the project out. The last info I read about the project looking at this was here and no answer has been given since. I did not want to post what I think is wrong unless I can read through the server code and would like to use VS2003 for its GUI features. I just did a "find /I "win32" in the "sched" folder and it appears that code is all Linux so I cant use vs2013 for debugging I have a suspicion that it is not a bug but a way to reduce load on the database but that is a guess. If a real bug I think I know what has happened. ID: 93312 · |
|
Send message Joined: 5 Oct 06 Posts: 5164
|
An alternative way of handling that is to paste the search phrase "last request too recent" (with the quotation marks in this case) into the low-contrast search box at the top left of the GitHub screen (beside the 'black cat' logo). That gave me the two hits in sched/handle_request.cpp that you quoted. Most of the server code that BOINC users will be interested in is in that 'sched' folder. It also found that the phrase had appeared in three bug-report 'issues' - one recent, and the other two both over a decade old. There's no difference between Linux code and Windows code - it's all just ASCII text. One difference that trips Windows users up is in the line termination convention used in text files: Windows uses the character pair CRLF, whereas Linux uses a single CR character. Notepad++ is a useful Windows tool which can display either format without batting an eyelid - and convert between the storage formats on disk whenever needed. Going back to the query about "last request too recent": servers always issue a "Don't bother me for xxx seconds" instruction after every contact. The value of xxx is set by the project: it varies from 7 seconds at SETI Beta, to 303 seconds at SETI, to an hour at CPDN (last time I looked). It's there to protect against effective DDoS attacks by BOINC clients. If you do make a second request too soon, everything works as normal, except that you won't be allocated any new work. You have to wait for another timeout interval. The commonest time I see it is if I'm doing maintenance, and have to restart the BOINC client. The client doesn't remember where it is in the backoff cycle when restarted, and is capable of requesting new work before the server is willing to send it. ID: 93313 · |
|
Joseph Stateson Send message Joined: 27 Jun 08 Posts: 642
|
I have been trying to debug why no work is downloaded from milkyway when completed results are uploaded. AFAICT other projects download a few (or a bunch!) on every upload. Not milkyway, and that was the topic of that thread I listed. From trial and error, I, and others, have observed that MW does not respond to an update unless about 160 seconds have elapsed since the last request for data and that request must be after all the data is uploaded (or lost) Users consider this a bug in the server and that it is compounded by boinc waiting for about 15-20 minutes to elapse before asking a second time. My guess was that Milkyway was considering the upload of "completed results" to be the start time of the "last request". I got to looking the windows code since I can finally build the client in VS2013. Looked at: schedule_op, cs_schedule and work_fetch I noticed that the field "req_secs" was used by the client to report "not asking for tasks" That field was defined as number of seconds of data that the device wants. Tried the following: Made a mod the client so that "req_secs" was always 0 when sent to the project. Added another client mod to the "piggyback" routine so that when I clicked on "update" the field req_secs was set to a big number of seconds. The idea being that every time data was uploaded to Milkyway there would be no "want more data" but when I manually did an update it would ask for data (req_secs > 0). Anyway, it didn't work, nothing got downloaded. A previous mod I tried was also unsuccessful: I allowed 3 minutes of data to accumulated before allowing an upload. Again, nothing got downloaded. I have decided there are other challenges more interesting. I do have my own solution to the MW problem: I set a rule in BoincTasks that waits 160 seconds after the last Milkyway tasks is completed and then issues an RPC update. Since BT itself only checks every couple of minutes there is a worst case of 5-6 minutes of idle time before additional stuff gets downloaded and executed as shown in picture below. Other users simply use a dos script on the local system and loop boinccmd.exe to issue an update every 160 seconds. While this works, I do have 6 GPUs that are idle for 7 minutes and that represents just over 42 work units. I used to let Einstein run with "0" resource but recently some of their task take an unusual amount of time to finish. My idle time of 6 minutes is livable. The 15 to 20 minute wait was unacceptable. 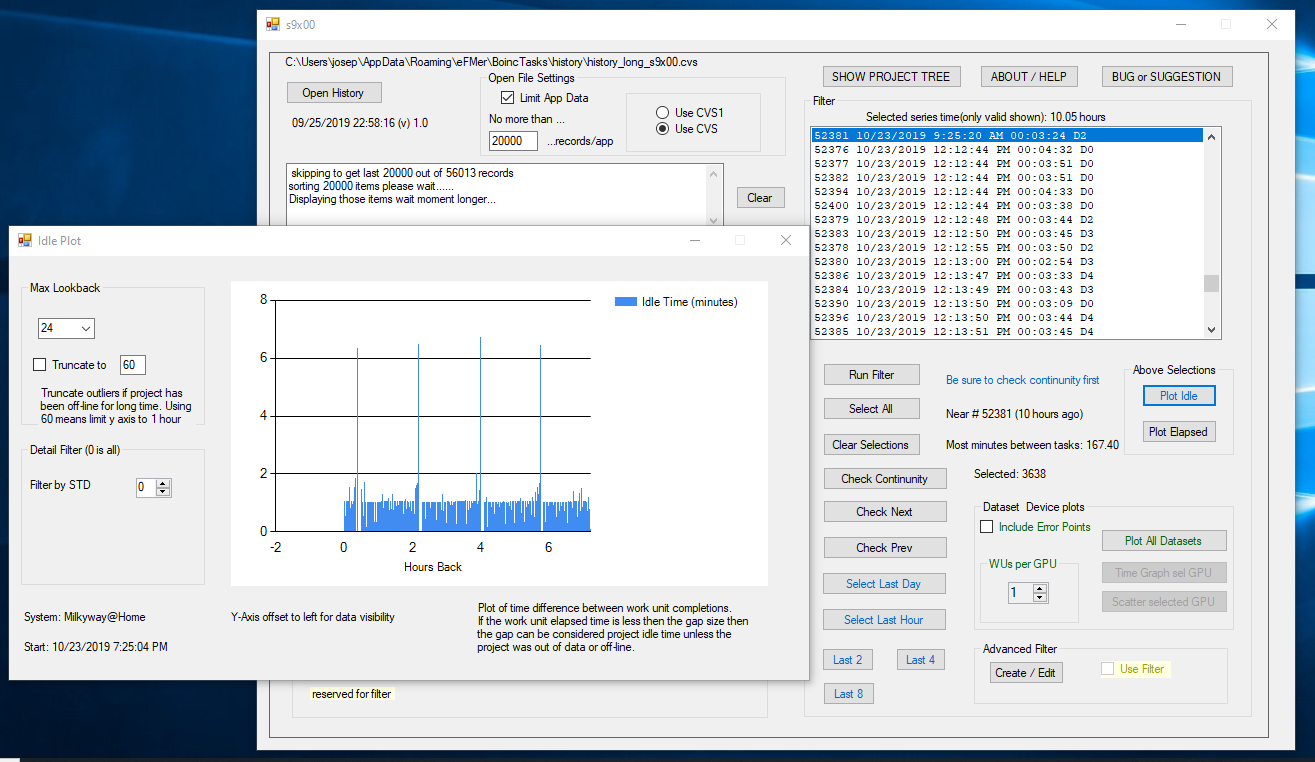 ID: 93314 · |
|
Send message Joined: 5 Oct 06 Posts: 5164
|
Absolutely. Work is always allocated as the result of a REQUEST. Not by a whim of the server. The simplest way to monitor it is to set the <sched_op_debug> logging flag. 26/10/2019 07:10:29 | NumberFields@home | [sched_op] CPU work request: 1192.03 seconds; 0.00 devices 26/10/2019 07:10:29 | NumberFields@home | [sched_op] NVIDIA GPU work request: 0.00 seconds; 0.00 devices 26/10/2019 07:10:29 | NumberFields@home | [sched_op] Intel GPU work request: 0.00 seconds; 0.00 devices 26/10/2019 08:12:26 | SETI@home | [sched_op] CPU work request: 0.00 seconds; 0.00 devices 26/10/2019 08:12:26 | SETI@home | [sched_op] NVIDIA GPU work request: 8674.68 seconds; 0.00 devices 26/10/2019 08:12:26 | SETI@home | [sched_op] Intel GPU work request: 0.00 seconds; 0.00 devices 26/10/2019 04:32:28 | Einstein@Home | [sched_op] CPU work request: 0.00 seconds; 0.00 devices 26/10/2019 04:32:28 | Einstein@Home | [sched_op] NVIDIA GPU work request: 0.00 seconds; 0.00 devices 26/10/2019 04:32:28 | Einstein@Home | [sched_op] Intel GPU work request: 4325.95 seconds; 0.00 devicesYou only get work if you ask. And if you ask for work for a device that the project supports. And if the project has the right kind of work available at the instant you ask. Bit it starts with an ask. ID: 93315 · |
|
Send message Joined: 5 Oct 06 Posts: 5164
|
And a note on timing. The three requests I just posted ended with 26/10/2019 04:32:30 | Einstein@Home | Project requested delay of 60 seconds 26/10/2019 07:10:32 | NumberFields@home | Project requested delay of 61 seconds 26/10/2019 08:12:28 | SETI@home | Project requested delay of 303 secondsDifferent projects, different delays. The client internally maintains a 60 seconds polling loop: unless something else happens, it may be up to 60 seconds after the end of the project requested delay before any work request is made. And the first request might be to a different project. There's usually a five second pause between requests to different projects. ID: 93316 · |
|
Dave Send message Joined: 28 Jun 10 Posts: 3342
|
I can confirm that the delay is one hour (or to be precise 61minutes) on CPDN. Another reason for this is it reduces the damage caused by serial crashers of tasks. (Mostly Linux boxes without the 32bit libs) ID: 93317 · |
|
Send message Joined: 5 Oct 06 Posts: 5164
|
You'll probably find that the CPDN admins set a one hour delay exactly - and that the BOINC server code then added a 1% margin for error. Not every computer clock runs perfectly, and we wouldn't want a fast-running clock to send premature requests - and have them rejected. ID: 93318 · |
|
Dave Send message Joined: 28 Jun 10 Posts: 3342
|
You'll probably find that the CPDN admins set a one hour delay exactly - and that the BOINC server code then added a 1% margin for error. Not every computer clock runs perfectly, and we wouldn't want a fast-running clock to send premature requests - and have them rejected. Thanks Richard, I had wondered about the extra one minute. ID: 93320 · |
Copyright © 2026 University of California.
Permission is granted to copy, distribute and/or modify this document
under the terms of the GNU Free Documentation License,
Version 1.2 or any later version published by the Free Software Foundation.